Prometheus | 融合监控实战风云录!
本文将会介绍【优维监控实践】,针对金融行业的场景需求,结合落地应用经验,构建基于Prometheus的大规模线上业务交易监控能力。
集群化方案现状

集群化高可用建设思路
# 联邦集群方案
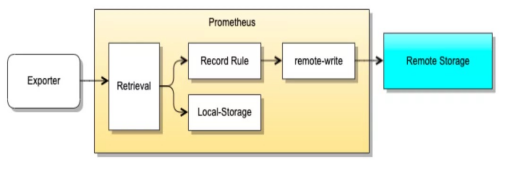
# 远端存储方案
远端存储方案需要解决的问题
# 自身有着容量上限
# 数据量越大,查询分析的压力也越大
远端存储解决方案
# 减少指标量级
# 提升架构性能
# 降维指标
# 选择聚合算子
业务交易量的指标类型为Histogram,用于统计每一个模块处理交易请求的数量与响应时间,获得分位值数据。
自动扩展的分片采集
# 分片采集服务

# 交易服务采集集群
# 非交易服务采集集群
流式计算引入
# Flink引入
# 采集服务
# 转发服务
# 流式计算服务
# 存储服务
# 报警服务
本文初步介绍
基于Prometheus技术方案
针对大规模业务监控场景
优维监控实践建设思路
优维将会持续深入分析应用场景
从各环节的技术细节出发
继续构建高标准的监控系统
不忘初心 赋能业务
优维监控 敬请期待















